
Dear colleagues, Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness. Say that the display I desire is like this: vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R How do I get there? I am surprised to find no guidance in the TEI guidelines. I have imagined the following two encoding approaches. What do you think? APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app> APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> Thanks and best wishes, Arlo

Dear Arlo, I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): [image: image.png] and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: [image: image.png] The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this. I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult. Andrew On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net> wrote:
Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
{kind=link}
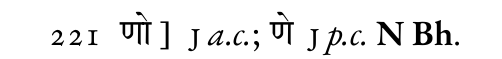{kind=link}

Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose ( https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...) involves the use of the TEI element <witDetail> ( https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly. All best, Dan On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com> wrote:
Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): [image: image.png] and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: [image: image.png]
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net> wrote:
Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
{kind=link}
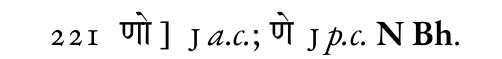{kind=link}
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project! On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com> wrote:
Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose ( https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...) involves the use of the TEI element <witDetail> ( https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use
<app>
<lem wit=”#P #Q”>vijayaḥ</lem>
<rdg wit=”#P”>vajayaḥ</rdg>
<witDetail wit="#P">ac</witDetail>
<rdg wit=”#R”>vajayo</rdg>
</app>
--- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler;
or,
<app>
<lem wit=”#P #Q”>vijayaḥ</lem>
<witDetail wit="#P">pc</witDetail>
<rdg wit=”#P”>vajayaḥ</rdg>
<witDetail wit="#P">ac</witDetail>
<rdg wit=”#R”>vajayo</rdg>
</app>
-- assuming that both the PC and the AC readings need to be tagged explicitly.
All best,
Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com> wrote:
Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): [image: image.png] and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: [image: image.png]
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net> wrote:
Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
{kind=link}
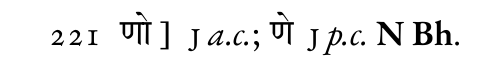{kind=link}
Dear Dan and Andrew, Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way? <witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/> Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies. Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>: ‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’ Examples: <lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem> This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows: <lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem> Thanks in advance for further feedback on the pros and cons of either method. Best wishes, Arlo Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com<mailto:andrew.ollett@gmail.com>> a écrit : Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project! On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com<mailto:danbalogh@gmail.com>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem<https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg<https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly. All best, Dan On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com<mailto:andrew.ollett@gmail.com>> wrote: Dear Arlo, I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png> The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this. I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult. Andrew On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net<mailto:arlo.griffiths@efeo.net>> wrote: Dear colleagues, Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness. Say that the display I desire is like this: vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R How do I get there? I am surprised to find no guidance in the TEI guidelines. I have imagined the following two encoding approaches. What do you think? APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app> APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> Thanks and best wishes, Arlo _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org<mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org<mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net> wrote:
Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com> wrote:
Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose ( https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...) involves the use of the TEI element <witDetail> ( https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or,
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com> wrote:
Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri...
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net> wrote:
Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts

sic and corr are used for the critical editors corrections and designations of something as read. They are not for use of in designating the changes made by a manuscript scribe. To designate changes in a manuscript, use del and add instead. So if the scribe corrected vajaya to vijaya one would write: v<del>a</del><add>i</add>jaya or perhaps if one wants to take syllables as the unit of correction: <del>va</del><add>vi</add>jaya This would then be the content of the witness. ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jan 2021, at 11:26 PM, Dániel Balogh <danbalogh@gmail.com> wrote:
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan
On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>> wrote: Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com <mailto:danbalogh@gmail.com>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata>), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW>), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>> wrote: Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>> wrote: Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts

Dear Peter, thanks for pointing this out! It led me to two relevant sections of the TEI Guidelines, “11.3.1.4 Additions and Deletions”[1] and “11.3.1.5 Substitutions”[2]. They discuss an example that seems to fit the present problem quite well: “““ One must have lived longer with <subst> <del seq="1">this</del> <del seq="2"> <add seq="1">such a</add> </del> <add seq="2">a</add> </subst> system, to appreciate its advantages. ””” This expresses a sequence of changes: “this -> such a -> a” What’s helpful here is that the TEI Guidelines also give an example of how to express that with a tei:app element (right at the bottom of section 11.3.1.5): “““ One must have lived longer with <app> <rdg varSeq="1"> <del>this</del> </rdg> <rdg varSeq="2"> <del> <add>such a</add> </del> </rdg> <rdg varSeq="3"> <add>a</add> </rdg> </app> system, to appreciate its advantages. ””” This example is only about a single witness. Perhaps an application to Arlo’s case could look like this: “““ <app> <lem wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ””” It’s still not easy to see that witness P supports the chosen reading, however. You could add a @sameAs (or @corresp) linking to the reading you think is right: “““ <app> <lem xml:id="lem1" wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2" sameAs="#lem1"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ””” The approach with tei:witDetail is certainly one that’s found in the TEI Guidelines. But I find that it is very hard to deal with in processing. I usually just treat it as a note for a particular witness, and tack it onto the end of the apparatus entry. It seems that it’s mainly the text content that determines the meaning of tei:witDetail (hence the doubts about @type="pc" etc.). I suppose if you are working with a large set of editions you’ll want to express as much of your editorial work in the structure of the markup, and not leave it up to the prose inside any element to determine its relevance for your editorial decisions. I was using something like the following myself, but in view of the present discussion I’m rethinking this approach: “““ <p>... <anchor xml:id="A"/>vijayaḥ<anchor xml:id="B"/> ...</p> <app from="#A" to="#B"> <lem>vijayaḥ</lem> <rdgGrp type="supports"> <rdg wit="#Q">vijayaḥ</rdg> <rdg wit="#P"><add>vi</add>jayaḥ</rdg> </rdgGrp> <rdgGrp type="opposes"> <rdg wit="#P"><del>va</del>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </rdgGrp> </app> ””” This is somewhat more verbose, but for me this was the easiest starting point to get a typeset version from: it avoids the @wit on the tei:lem, because (in this @from @to approach, the “double-end-point-attached method”), the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition. The use of tei:rdgGrp is more work to encode, but it’s helpful since it corresponds nicely to the left (pro) and right (con) part, and the supporting/opposing readings all go into separate tei:rdg elements. Arlo’s (and I guess most people’s) expectation for the display was:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
It seems to me that the approach with tei:rdgGrp-s is the closest to this in structural terms. With best wishes, On Sat, Jan 16 2021, Peter Scharf wrote:
sic and corr are used for the critical editors corrections and designations of something as read. They are not for use of in designating the changes made by a manuscript scribe. To designate changes in a manuscript, use del and add instead. So if the scribe corrected vajaya to vijaya one would write:
v<del>a</del><add>i</add>jaya
or perhaps if one wants to take syllables as the unit of correction:
<del>va</del><add>vi</add>jaya
This would then be the content of the witness.
****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jan 2021, at 11:26 PM, Dániel Balogh <danbalogh@gmail.com> wrote:
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan
On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>> wrote: Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com <mailto:danbalogh@gmail.com>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata>), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW>), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>> wrote: Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>> wrote: Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD [2] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU -- Patrick McAllister long-term email: pma@rdorte.org
Dear Patrick and colleagues, Thanks, Patrick, for spelling out the details of the use of the subst, del, and add tags. However, I’m confused by the statement at the end of your message, “the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.” In my understanding, the content of the lem-element is the accepted text of the edition. Moreover, to indicate that a particular ms. supports that reading the simplest way is to include the sigla as the content of the wit-attribute in the lem element. Perhaps you can clarify what you intended. Yours, Peter ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 18 Jan 2021, at 4:08 PM, Patrick McAllister <pma@rdorte.org> wrote:
Dear Peter,
thanks for pointing this out! It led me to two relevant sections of the TEI Guidelines, “11.3.1.4 Additions and Deletions”[1] and “11.3.1.5 Substitutions”[2]. They discuss an example that seems to fit the present problem quite well:
“““ One must have lived longer with <subst> <del seq="1">this</del> <del seq="2"> <add seq="1">such a</add> </del> <add seq="2">a</add> </subst> system, to appreciate its advantages. ”””
This expresses a sequence of changes: “this -> such a -> a”
What’s helpful here is that the TEI Guidelines also give an example of how to express that with a tei:app element (right at the bottom of section 11.3.1.5):
“““ One must have lived longer with <app> <rdg varSeq="1"> <del>this</del> </rdg> <rdg varSeq="2"> <del> <add>such a</add> </del> </rdg> <rdg varSeq="3"> <add>a</add> </rdg> </app> system, to appreciate its advantages. ”””
This example is only about a single witness. Perhaps an application to Arlo’s case could look like this:
“““ <app> <lem wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
It’s still not easy to see that witness P supports the chosen reading, however. You could add a @sameAs (or @corresp) linking to the reading you think is right:
“““ <app> <lem xml:id="lem1" wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2" sameAs="#lem1"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
The approach with tei:witDetail is certainly one that’s found in the TEI Guidelines. But I find that it is very hard to deal with in processing. I usually just treat it as a note for a particular witness, and tack it onto the end of the apparatus entry. It seems that it’s mainly the text content that determines the meaning of tei:witDetail (hence the doubts about @type="pc" etc.). I suppose if you are working with a large set of editions you’ll want to express as much of your editorial work in the structure of the markup, and not leave it up to the prose inside any element to determine its relevance for your editorial decisions.
I was using something like the following myself, but in view of the present discussion I’m rethinking this approach:
“““ <p>... <anchor xml:id="A"/>vijayaḥ<anchor xml:id="B"/> ...</p>
<app from="#A" to="#B"> <lem>vijayaḥ</lem> <rdgGrp type="supports"> <rdg wit="#Q">vijayaḥ</rdg> <rdg wit="#P"><add>vi</add>jayaḥ</rdg> </rdgGrp> <rdgGrp type="opposes"> <rdg wit="#P"><del>va</del>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </rdgGrp> </app> ”””
This is somewhat more verbose, but for me this was the easiest starting point to get a typeset version from: it avoids the @wit on the tei:lem, because (in this @from @to approach, the “double-end-point-attached method”), the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.
The use of tei:rdgGrp is more work to encode, but it’s helpful since it corresponds nicely to the left (pro) and right (con) part, and the supporting/opposing readings all go into separate tei:rdg elements.
Arlo’s (and I guess most people’s) expectation for the display was:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
It seems to me that the approach with tei:rdgGrp-s is the closest to this in structural terms.
With best wishes,
On Sat, Jan 16 2021, Peter Scharf wrote:
sic and corr are used for the critical editors corrections and designations of something as read. They are not for use of in designating the changes made by a manuscript scribe. To designate changes in a manuscript, use del and add instead. So if the scribe corrected vajaya to vijaya one would write:
v<del>a</del><add>i</add>jaya
or perhaps if one wants to take syllables as the unit of correction:
<del>va</del><add>vi</add>jaya
This would then be the content of the witness.
****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jan 2021, at 11:26 PM, Dániel Balogh <danbalogh@gmail.com> wrote:
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan
On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com <mailto:danbalogh@gmail.com> <mailto:danbalogh@gmail.com <mailto:danbalogh@gmail.com>>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata>>), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW> <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW>>), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html>> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> wrote: Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs><https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>> _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD>
[2] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU>
-- Patrick McAllister long-term email: pma@rdorte.org <mailto:pma@rdorte.org>
On Mon, Jan 18 2021, Peter Scharf wrote:
Dear Patrick and colleagues, Thanks, Patrick, for spelling out the details of the use of the subst, del, and add tags. However, I’m confused by the statement at the end of your message, “the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.” In my understanding, the content of the lem-element is the accepted text of the edition. Moreover, to indicate that a particular ms. supports that reading the simplest way is to include the sigla as the content of the wit-attribute in the lem element. Perhaps you can clarify what you intended.
I made that remark because of how the double-end-point-attachment method differs from the parallel segmentation method, where the tei:lem has a different meaning. With respect to the latter method, your observations are perfectly correct. Section “12.1.2 Readings”[1] explains the situation: “The lem element may also be used to record the base text of the source edition, to mark the readings of a base witness, to indicate the preference of an editor or encoder for a particular reading, or (e.g. in the case of an external apparatus) to indicate precisely to which portion of the main text the variation applies. Those who prefer to work without the notion of a base text or who are not using the parallel segmentation method may prefer not to use it at all. How it is used depends in part on the method chosen for linking the apparatus to the text; for more information, see section 12.2 Linking the Apparatus to the Text.” So, the tei:lem has different functions, depending on different factors (some just practical, as in the case of how to link apparatus and text). The example I gave didn’t use the parallel segmentation method, and so the tei:lem wasn’t doing anything very useful. The “vijayaḥ” occurred twice in that example: once in the paragraph, surrounded by anchors, and once in the lemma element. The mention in the lemma would only appear in the apparatus, e.g., the part typically printed after the line numbers: “1–2 vijayaḥ] ...witnesses ...”. In this case, the characters in the paragraph represent the accepted reading, and not the content of the tei:lem. The only strong reason (in my opinion) for using tei:lem at all in this method is to abbreviate longish readings in the apparatus: “““ <p><anchor xml:id="a"/>a b c d e f<anchor xml:id="f"/></p> <app from="#a" to="#b"> <lem>a...f</lem> ... </app> ””” The “\lemma” command in (re)ledmac in LaTeX is very similar to how tei:lem is used in an external TEI apparatus: \edtext{A B C D E F}{\lemma{A...F}\Afootnote{...}} Hope that clears it up!
On 18 Jan 2021, at 4:08 PM, Patrick McAllister <pma@rdorte.org> wrote:
Dear Peter,
thanks for pointing this out! It led me to two relevant sections of the TEI Guidelines, “11.3.1.4 Additions and Deletions”[1] and “11.3.1.5 Substitutions”[2]. They discuss an example that seems to fit the present problem quite well:
“““ One must have lived longer with <subst> <del seq="1">this</del> <del seq="2"> <add seq="1">such a</add> </del> <add seq="2">a</add> </subst> system, to appreciate its advantages. ”””
This expresses a sequence of changes: “this -> such a -> a”
What’s helpful here is that the TEI Guidelines also give an example of how to express that with a tei:app element (right at the bottom of section 11.3.1.5):
“““ One must have lived longer with <app> <rdg varSeq="1"> <del>this</del> </rdg> <rdg varSeq="2"> <del> <add>such a</add> </del> </rdg> <rdg varSeq="3"> <add>a</add> </rdg> </app> system, to appreciate its advantages. ”””
This example is only about a single witness. Perhaps an application to Arlo’s case could look like this:
“““ <app> <lem wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
It’s still not easy to see that witness P supports the chosen reading, however. You could add a @sameAs (or @corresp) linking to the reading you think is right:
“““ <app> <lem xml:id="lem1" wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2" sameAs="#lem1"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
The approach with tei:witDetail is certainly one that’s found in the TEI Guidelines. But I find that it is very hard to deal with in processing. I usually just treat it as a note for a particular witness, and tack it onto the end of the apparatus entry. It seems that it’s mainly the text content that determines the meaning of tei:witDetail (hence the doubts about @type="pc" etc.). I suppose if you are working with a large set of editions you’ll want to express as much of your editorial work in the structure of the markup, and not leave it up to the prose inside any element to determine its relevance for your editorial decisions.
I was using something like the following myself, but in view of the present discussion I’m rethinking this approach:
“““ <p>... <anchor xml:id="A"/>vijayaḥ<anchor xml:id="B"/> ...</p>
<app from="#A" to="#B"> <lem>vijayaḥ</lem> <rdgGrp type="supports"> <rdg wit="#Q">vijayaḥ</rdg> <rdg wit="#P"><add>vi</add>jayaḥ</rdg> </rdgGrp> <rdgGrp type="opposes"> <rdg wit="#P"><del>va</del>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </rdgGrp> </app> ”””
This is somewhat more verbose, but for me this was the easiest starting point to get a typeset version from: it avoids the @wit on the tei:lem, because (in this @from @to approach, the “double-end-point-attached method”), the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.
The use of tei:rdgGrp is more work to encode, but it’s helpful since it corresponds nicely to the left (pro) and right (con) part, and the supporting/opposing readings all go into separate tei:rdg elements.
Arlo’s (and I guess most people’s) expectation for the display was:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
It seems to me that the approach with tei:rdgGrp-s is the closest to this in structural terms.
With best wishes,
On Sat, Jan 16 2021, Peter Scharf wrote:
sic and corr are used for the critical editors corrections and designations of something as read. They are not for use of in designating the changes made by a manuscript scribe. To designate changes in a manuscript, use del and add instead. So if the scribe corrected vajaya to vijaya one would write:
v<del>a</del><add>i</add>jaya
or perhaps if one wants to take syllables as the unit of correction:
<del>va</del><add>vi</add>jaya
This would then be the content of the witness.
****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jan 2021, at 11:26 PM, Dániel Balogh <danbalogh@gmail.com> wrote:
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan
On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com <mailto:danbalogh@gmail.com> <mailto:danbalogh@gmail.com <mailto:danbalogh@gmail.com>>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata>>), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW> <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW>>), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html>> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> wrote: Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs><https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>> _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD>
[2] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU>
-- Patrick McAllister long-term email: pma@rdorte.org <mailto:pma@rdorte.org>
Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/TC.html#TCAPLR -- Patrick McAllister long-term email: pma@rdorte.org
Yes, thanks. I wasn’t aware of the double-end-point-attachment method. ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 18 Jan 2021, at 6:51 PM, Patrick McAllister <pma@rdorte.org> wrote:
On Mon, Jan 18 2021, Peter Scharf wrote:
Dear Patrick and colleagues, Thanks, Patrick, for spelling out the details of the use of the subst, del, and add tags. However, I’m confused by the statement at the end of your message, “the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.” In my understanding, the content of the lem-element is the accepted text of the edition. Moreover, to indicate that a particular ms. supports that reading the simplest way is to include the sigla as the content of the wit-attribute in the lem element. Perhaps you can clarify what you intended.
I made that remark because of how the double-end-point-attachment method differs from the parallel segmentation method, where the tei:lem has a different meaning. With respect to the latter method, your observations are perfectly correct.
Section “12.1.2 Readings”[1] explains the situation:
“The lem element may also be used to record the base text of the source edition, to mark the readings of a base witness, to indicate the preference of an editor or encoder for a particular reading, or (e.g. in the case of an external apparatus) to indicate precisely to which portion of the main text the variation applies. Those who prefer to work without the notion of a base text or who are not using the parallel segmentation method may prefer not to use it at all. How it is used depends in part on the method chosen for linking the apparatus to the text; for more information, see section 12.2 Linking the Apparatus to the Text.”
So, the tei:lem has different functions, depending on different factors (some just practical, as in the case of how to link apparatus and text).
The example I gave didn’t use the parallel segmentation method, and so the tei:lem wasn’t doing anything very useful.
The “vijayaḥ” occurred twice in that example: once in the paragraph, surrounded by anchors, and once in the lemma element. The mention in the lemma would only appear in the apparatus, e.g., the part typically printed after the line numbers: “1–2 vijayaḥ] ...witnesses ...”. In this case, the characters in the paragraph represent the accepted reading, and not the content of the tei:lem.
The only strong reason (in my opinion) for using tei:lem at all in this method is to abbreviate longish readings in the apparatus:
“““ <p><anchor xml:id="a"/>a b c d e f<anchor xml:id="f"/></p> <app from="#a" to="#b"> <lem>a...f</lem> ... </app> ”””
The “\lemma” command in (re)ledmac in LaTeX is very similar to how tei:lem is used in an external TEI apparatus:
\edtext{A B C D E F}{\lemma{A...F}\Afootnote{...}}
Hope that clears it up!
On 18 Jan 2021, at 4:08 PM, Patrick McAllister <pma@rdorte.org> wrote:
Dear Peter,
thanks for pointing this out! It led me to two relevant sections of the TEI Guidelines, “11.3.1.4 Additions and Deletions”[1] and “11.3.1.5 Substitutions”[2]. They discuss an example that seems to fit the present problem quite well:
“““ One must have lived longer with <subst> <del seq="1">this</del> <del seq="2"> <add seq="1">such a</add> </del> <add seq="2">a</add> </subst> system, to appreciate its advantages. ”””
This expresses a sequence of changes: “this -> such a -> a”
What’s helpful here is that the TEI Guidelines also give an example of how to express that with a tei:app element (right at the bottom of section 11.3.1.5):
“““ One must have lived longer with <app> <rdg varSeq="1"> <del>this</del> </rdg> <rdg varSeq="2"> <del> <add>such a</add> </del> </rdg> <rdg varSeq="3"> <add>a</add> </rdg> </app> system, to appreciate its advantages. ”””
This example is only about a single witness. Perhaps an application to Arlo’s case could look like this:
“““ <app> <lem wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
It’s still not easy to see that witness P supports the chosen reading, however. You could add a @sameAs (or @corresp) linking to the reading you think is right:
“““ <app> <lem xml:id="lem1" wit="#Q">vijayaḥ</lem> <rdg wit="#P" varSeq="1"><del>va</del>jayaḥ</rdg> <rdg wit="#P" varSeq="2" sameAs="#lem1"><add>vi</add>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </app> ”””
The approach with tei:witDetail is certainly one that’s found in the TEI Guidelines. But I find that it is very hard to deal with in processing. I usually just treat it as a note for a particular witness, and tack it onto the end of the apparatus entry. It seems that it’s mainly the text content that determines the meaning of tei:witDetail (hence the doubts about @type="pc" etc.). I suppose if you are working with a large set of editions you’ll want to express as much of your editorial work in the structure of the markup, and not leave it up to the prose inside any element to determine its relevance for your editorial decisions.
I was using something like the following myself, but in view of the present discussion I’m rethinking this approach:
“““ <p>... <anchor xml:id="A"/>vijayaḥ<anchor xml:id="B"/> ...</p>
<app from="#A" to="#B"> <lem>vijayaḥ</lem> <rdgGrp type="supports"> <rdg wit="#Q">vijayaḥ</rdg> <rdg wit="#P"><add>vi</add>jayaḥ</rdg> </rdgGrp> <rdgGrp type="opposes"> <rdg wit="#P"><del>va</del>jayaḥ</rdg> <rdg wit="#R">vajayo</rdg> </rdgGrp> </app> ”””
This is somewhat more verbose, but for me this was the easiest starting point to get a typeset version from: it avoids the @wit on the tei:lem, because (in this @from @to approach, the “double-end-point-attached method”), the content of tei:lem becomes the actual lemma in the apparatus, but is not also the accepted text of the edition.
The use of tei:rdgGrp is more work to encode, but it’s helpful since it corresponds nicely to the left (pro) and right (con) part, and the supporting/opposing readings all go into separate tei:rdg elements.
Arlo’s (and I guess most people’s) expectation for the display was:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
It seems to me that the approach with tei:rdgGrp-s is the closest to this in structural terms.
With best wishes,
On Sat, Jan 16 2021, Peter Scharf wrote:
sic and corr are used for the critical editors corrections and designations of something as read. They are not for use of in designating the changes made by a manuscript scribe. To designate changes in a manuscript, use del and add instead. So if the scribe corrected vajaya to vijaya one would write:
v<del>a</del><add>i</add>jaya
or perhaps if one wants to take syllables as the unit of correction:
<del>va</del><add>vi</add>jaya
This would then be the content of the witness.
****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jan 2021, at 11:26 PM, Dániel Balogh <danbalogh@gmail.com> wrote:
Dear Arlo, to your first question, I think it would be best to ask a TEI expert. Maybe one will speak up here; or you could try Axelle. Given the TEI guidelines, I think putting "pc" and so forth as the contents of witDetail is the officially endorsed method. For the second question, I am even less qualified to give an authoritative answer, except that if you do choose to go the second way, i.e. instead of @type on <lem> you use tags within lem, then I think "conj" should correspond to supplied rather than to corr with or without an attribute. Best, Dan
On Fri, 15 Jan 2021 at 18:46, Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear Dan and Andrew,
Wonderful. We’ll adopt that use of <witDetail> in the DHARMA Encoding Guide for Critical Editions, but whould it not be better to do it in this way?
<witDetail wit="#P" type="ac"/> <witDetail wit="#P" type="pc"/>
Andrew’s version of my approach 2 would not have worked for us, for the reason that Andrew points out himself, that a given <lem> or <rdg> may be supported by more than one witness, and the @type would not succeed in making clear to which of the witnesses the label ac/pc applies.
Also, in our Encoding Guide as it stands now we have prescribed the following use of @type on <lem>:
‘If the adopted reading is not directly supported by any of the witnesses, then you must apply to the <lem> an attribute @type. The permitted values are “norm”, “conj” and “emn”, respectively for normalization, conjecture and emendation.’
Examples:
<lem type=“norm”>pariśrānto ’pi</lem> <lem type=“emn”>pariśrānto ’pi</lem> <lem type=“conj”>pariśrānto ’pi</lem>
This discussion now has made me wonder whether it would perhaps be preferable to encode those three scenarios as follows:
<lem><reg>pariśrānto ’pi</reg</lem> <lem><corr cert="low">pariśrānto ’pi</corr</lem> <lem><corr>pariśrānto ’pi</corr</lem>
Thanks in advance for further feedback on the pros and cons of either method.
Best wishes,
Arlo
Le 15 janv. 2021 à 17:15, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> a écrit :
Hmm, Dániel’s suggestion of witDetail seems like it's the most straightforward and most TEI-compliant. I'll have to start using it in my project!
On Fri, Jan 15, 2021 at 10:06 AM Dániel Balogh <danbalogh@gmail.com <mailto:danbalogh@gmail.com> <mailto:danbalogh@gmail.com <mailto:danbalogh@gmail.com>>> wrote: Hello, while I have no experience with critical editions in TEI, I can't resist chiming in. My first thought was that witnesses should be defined separately for P, Pac and Ppc. This may be a bit cumbersome, but it gets what you want without hacking TEI, and is methodologically simple. I've had a look at the Digital Latin Library linked by Andrew, and it seems that this is one of the two methods they propose (https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-as-metadata>>), while their other method (in the section to which Andrew links, https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs> <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>) involves the use of the TEI element <witDetail> (https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW> <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/TC.html#TCAPLW>>), which seems to be the proper TEI-sanctioned method for adding anything about a particular witness at a particular spot, including but not limited to "ac" and "pc". Having thought a bit about this, I think your encoding use this latter method. According to TEI, witDetail is " a specialized note, which can be linked to both a reading and to one or more of the witnesses for that reading " and which " refers to the closest preceding lem <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-lem.html>> or rdg <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html <https://www.tei-c.org/release/doc/tei-p5-doc/en/html/ref-rdg.html>>. " Thus, you might use
<app> <lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> --- assuming that a siglum by default means the PC reading, and only the AC reading needs to be indicated separately, to make your encoding simpler; or, <app> <lem wit=”#P #Q”>vijayaḥ</lem> <witDetail wit="#P">pc</witDetail> <rdg wit=”#P”>vajayaḥ</rdg> <witDetail wit="#P">ac</witDetail> <rdg wit=”#R”>vajayo</rdg> </app> -- assuming that both the PC and the AC readings need to be tagged explicitly.
All best, Dan
On Fri, 15 Jan 2021 at 16:38, Andrew Ollett <andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com> <mailto:andrew.ollett@gmail.com <mailto:andrew.ollett@gmail.com>>> wrote: Dear Arlo,
I have opted for solution #2 (marking corrections with @type, although in those cases I mark both the a.c. and p.c. reading with type): e.g. <app> <lem wit="#J" type="pc">मेत्ता</lem> <rdg wit="#J" type="ac">मत्ता</rdg> <rdg source="#N #Bh">मित्ता</rdg> </app> rendered (in XeLaTeX with reledmac): <image.png> and for the opposite situation: <app> <lem wit="#J" type="ac">णो</lem> <rdg wit="#J" type="pc" source="#N #Bh">णे</rdg> </app> rendered: <image.png>
The only problem with this is that the @type attribute applies to the entire rdg/lem element, which means that if there are other attributes indicating other manuscripts or sources (as the second example shows), nothing explicitly links "a.c." or "p.c." to the manuscript witness. In my setup I have a convention whereby these @type attributes are interpreted as "going with" with @wit attribute, not with the @source attribute, but in a situation where you have multiple witnesses, you might need to refine this.
I note that the Digital Latin Library has (independently) adopted a similar approach: https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-cri... <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs><https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs <https://digitallatin.github.io/guidelines/LDLT-Guidelines.html#apparatus-criticus-correction-specs>>
Another, probably better, option is to use <rdgGrp> for all of the readings of a particular witness, although this makes rendering/processing a little bit more difficult.
Andrew
On Fri, Jan 15, 2021 at 9:16 AM Arlo Griffiths <arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net> <mailto:arlo.griffiths@efeo.net <mailto:arlo.griffiths@efeo.net>>> wrote: Dear colleagues,
Say we have declared three witnesses P Q and R and we are facing a scenario whereby the accepted reading is in one case the result of scribal correction in the witness.
Say that the display I desire is like this:
vijayaḥ Ppc Q ◇ vajayaḥ Pac vajayo R
How do I get there? I am surprised to find no guidance in the TEI guidelines.
I have imagined the following two encoding approaches. What do you think?
APPROACH 1 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><sic>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P”><corr>vajayaḥ</corr></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
APPROACH 2 <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”ac”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app> and its counterpart if it is actually the ac reading that is accepted: <app>
<lem wit=”#P #Q”>vijayaḥ</lem> <rdg wit=”#P” type=”pc”>vajayaḥ</sic></rdg> <rdg wit=”#R”>vajayo</rdg> </app>
Thanks and best wishes,
Arlo
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>> _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> <mailto:Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org>> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts> <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHAD>
[2] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU <https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/PH.html#PHSU>
-- Patrick McAllister long-term email: pma@rdorte.org <mailto:pma@rdorte.org>
Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Footnotes: [1] https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/TC.html#TCAPLR
-- Patrick McAllister long-term email: pma@rdorte.org

Dear colleagues, There's a TEI discussion <https://github.com/TEIC/TEI/issues/1877> about a new element <ellipsis> to be added to the next edition of the TEI guidelines. The idea is that this tag would mark, "the purposeful indication in the source document that a passage has been omitted." or "when the source explicitly indicates `there is stuff missing here'." An example that has been shared is the poem in the middle of the central column of this page <https://hcmc.uvic.ca/~vicpoems/page_images/chambers_series_1/09/chambers_1_09_463_376_song.jpg>, where there's a line of asterisks. They would be tagged <ellipsis>* * * *</ellipsis> We're looking for more examples. If you can quickly (before mid-August) lay your hand on a good, clear example from a Sanskrit text, I would be grateful to know about it. For example, MSS in which the scribe writes a little series of mātrā lines showing that he can't read those akṣaras in his exemplar at that point. I think that would count as ellipsis in the sense given above Best, Dominik
Dear Dominik, We used question marks to indicate unclear when we were not able to read the character, or we used the unclear element We used a gap element when the ms. was damaged We encountered empty headbars which I believe indicated that the scribe could not read his exemplar. Take a look at https://www.sanskritlibrary.org/catindex.html <https://www.sanskritlibrary.org/catindex.html>, UPenn item 2623, f15r and f15v. We write "writes an empty headbar where his model must have failed to insert syllables in red where space had been left for them.” Here we supplied the missing text in angle brackets [indicating we as editors made the insertion]. See our description of the final rubrics in both works 1 and 2. Yours, Peter ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org https://sanskritlibrary.org ******************************
On 15 Jul 2021, at 7:19 PM, Dominik Wujastyk <wujastyk@gmail.com> wrote:
Dear colleagues,
There's a TEI discussion <https://github.com/TEIC/TEI/issues/1877> about a new element <ellipsis> to be added to the next edition of the TEI guidelines. The idea is that this tag would mark,
"the purposeful indication in the source document that a passage has been omitted." or "when the source explicitly indicates `there is stuff missing here'."
An example that has been shared is the poem in the middle of the central column of this page <https://hcmc.uvic.ca/~vicpoems/page_images/chambers_series_1/09/chambers_1_09_463_376_song.jpg>, where there's a line of asterisks. They would be tagged
<ellipsis>* * * *</ellipsis>
We're looking for more examples. If you can quickly (before mid-August) lay your hand on a good, clear example from a Sanskrit text, I would be grateful to know about it.
For example, MSS in which the scribe writes a little series of mātrā lines showing that he can't read those akṣaras in his exemplar at that point. I think that would count as ellipsis in the sense given above
Best, Dominik _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Dear Dominik, We used question marks to indicate unclear when we were not able to read the character, or we used the unclear element We used a gap element when the ms. was damaged We encountered empty headbars which I believe indicated that the scribe could not read his exemplar. Take a look at https://www.sanskritlibrary.org/catindex.html <https://www.sanskritlibrary.org/catindex.html>, UPenn item 2623, f15r and f15v. We write "writes an empty headbar where his model must have failed to insert syllables in red where space had been left for them.” Here we supplied the missing text in angle brackets [indicating we as editors made the insertion]. See our description of the final rubrics in both works 1 and 2. Yours, Peter p.s. But more likely the scribe just left the blank spaces to fill in later with red ink but never got around to doing it. ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org <mailto:scharf@sanskritlibrary.org> https://sanskritlibrary.org <https://sanskritlibrary.org/> ******************************
On 15 Jul 2021, at 7:19 PM, Dominik Wujastyk <wujastyk@gmail.com <mailto:wujastyk@gmail.com>> wrote:
Dear colleagues,
There's a TEI discussion <https://github.com/TEIC/TEI/issues/1877> about a new element <ellipsis> to be added to the next edition of the TEI guidelines. The idea is that this tag would mark,
"the purposeful indication in the source document that a passage has been omitted." or "when the source explicitly indicates `there is stuff missing here'."
An example that has been shared is the poem in the middle of the central column of this page <https://hcmc.uvic.ca/~vicpoems/page_images/chambers_series_1/09/chambers_1_09_463_376_song.jpg>, where there's a line of asterisks. They would be tagged
<ellipsis>* * * *</ellipsis>
We're looking for more examples. If you can quickly (before mid-August) lay your hand on a good, clear example from a Sanskrit text, I would be grateful to know about it.
For example, MSS in which the scribe writes a little series of mātrā lines showing that he can't read those akṣaras in his exemplar at that point. I think that would count as ellipsis in the sense given above
Best, Dominik _______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org <mailto:Indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
Thanks for that example, <https://www.sanskritlibrary.org/LoadImage?type=cropped&key=penn.neh2008.penn2623&image=mscoll390_item2623_wk1_body0015_crop2> Peter, it will do nicely. Best, Dominik

Dear Dominik, I believe that we ought to include also cases in which the scribe omitted a series of akSaras because they were also missing in the antigraph. I've encountered several times the type of notation that Peter pointed out and I've always supposed that these is the case. I'm afraid I can't recall on the top of my head in which manuscripts in the CUL these mAtrA symbols occur. I Also, I'm not a big fan of replicating in the transcription the symbols found in manuscripts as is done with the asterisks in the example you mention. Instead I prefer to indicate the number of akSaras missing. Indeed we used the element <gap> with further attributes to indicate such cases precisely because there is no other element to do it. I'm not very fond anymore of the way we graphically rendered in the output the missing akSaras, but that's because we decided to follow the Leiden conventions as EpiDoc suggests. I'm seriously rethinking our choice and leaning more towards adopting the conventions used in the SHT volumes of the VOHD, but I'm also exploring the DHARMA project solutions and discussing the topic with the TST people. Best wishes, Camillo Best wishes, Camillo ________________________________ Dr Camillo A. Formigatti Information Analyst – FAMOUS Project Bodleian Libraries The Weston Library Broad Street, Oxford OX1 3BG Email: camillo.formigatti@bodleian.ox.ac.uk<mailto:camillo.formigatti@bodleian.ox.ac.uk> Tel. (office): 01865 (2)77208 www.bodleian.ox.ac.uk<http://www.bodleian.ox.ac.uk/> GROW YOUR MIND in Oxford University’s Gardens, Libraries and Museums www.mindgrowing.org<http://www.mindgrowing.org/> ________________________________ From: Indic-texts <indic-texts-bounces@lists.tei-c.org> on behalf of Dominik Wujastyk <wujastyk@gmail.com> Sent: Friday, July 16, 2021 5:03 AM To: Peter Scharf <scharf@sanskritlibrary.org> Cc: INDIC-TEXTS <indic-texts@lists.tei-c.org> Subject: Re: [Indic-texts] examples of true ellipsis Thanks for that example,<https://www.sanskritlibrary.org/LoadImage?type=cropped&key=penn.neh2008.penn2623&image=mscoll390_item2623_wk1_body0015_crop2> Peter, it will do nicely. Best, Dominik
Dear colleagues, I am trying to find a realistic path toward finalizing my digital edition of Vararuci’s Sārasamuccaya, an anthology of stanzas on Dharma (mainly from the Mahābhārata) transmitted on Bali, with Old Javanese paraphrase. The text was edited by Raghu Vira (1962). Raghu Vira. 1962. Sāra-Samuccaya (a Classical Indonesian Compendium of High Ideals). Śata-Piṭaka Series (Dvīpāntara-Piṭaka), 24 (7). New Delhi: International Academy of Indian Culture. This edition is in two scripts, Balinese and Devanagari, which need to be compared systematically because there are rather frequently variants vetween the two (suggestive of error in one of the two, my job being to determine which reading is more likely to have been found in the manuscripts). The edition has a critical apparatus that gives some variant readings for the Sanskrit stanzas and tries to match them with verses from the MBh critical edition as far as it had been published by the early 1960s. One of the most time consuming parts of my task as TEI editor is to double check the MBh parallels and encode the results of my findings. My XML code is here: <https://github.com/erc-dharma/tfd-nusantara-philology/blob/master/editions/DHARMA_CritEdSarasamuccayaVararuci.xml> A provisional display is here: <https://erc-dharma.github.io/tfd-nusantara-philology/output/critical-edition/html/DHARMA_CritEdSarasamuccayaVararuci.html> I don’t have at my disposal a TEI version corresponding to the GRETIL file mbh1-18u.htm — can one of you oblige? As long as I don’t have one, it means that (for my XML file to validate) I need to manually apply <lg> and <l> tags and assign @n values to all <l> tags for any MBh parallel to be cited under a given Sārasamuccaya stanza. This is a lot of work and a distraction from other parts of my main task, which is to check the accuracy of the romanized Sanskrit and Old Javanese, keyed from Raghu Vira’s edition, and watching out for any differences between the Balinese and the Devanagari readings. In this connection, I am wondering how useful it actually is, for instance, to quote MBh01,056.027 MBh18,005.052 yathā samudro bhagavān yathā ca himavān giriḥ khyātāv ubhau ratnanidhī tathā bhāratam ucyate below Sārasamuccaya stanza 2 yathā samudro’timahān yathā ca himavān giriḥ| ubhau ratnanidhī khyātau tathā bhāratam ucyate|| Disregarding for now the possible existence of significant variant readings both within the Mbh transmission and within that of the Sārasamuccaya (I haven’t yet checked), and how such data might be incorporated into my edition, the utility of citing the two parallel stanzas from the MBh critical edition is presumably twofold: (1) to communicate to the reader of my edition that the given stanza has parallels in the critical edition of the MBh and where those parallels can be found (2) to underline the difference of reading in pāda c To achieve purpose (1), I don’t need to quote the whole parallel. To achieve purpose (2), merely quoting the parallel is not very efficient. It would presumably be better to create an <app> inside the edition of the Sārasamuccaya and report the MBh reading as <rdg> — I am wondering if I should do all of the above or if <note corresp="MBh01,056.027 MBh18,005.052"> without actually citing the text of the MBh crit. ed. would be enough if I encode the variation of reading <app> inside the edition of the Sārasamuccaya stanza. I would be grateful for suggestions from experienced TEI editors on how to achieve a useful TEI edition while avoiding needless work that stands in the way of my finishing the job. Best wishes, Arlo Griffiths
Dear Arlo, I don’t see any “one right way” to do this. You seem to have two aims: point at a parallel, and record the differences. For *pointing* to the parallel, you have several options. You could just use the @corresp on the tei:quote, or also on the tei:lg, select an element in an edition that you’d have to prepare, e.g., ``` <quote corresp="path-to-your-mbh-in-tei.xml#MBh01-056-027 path-to-your-mbh-in-tei.xml#MBh18-005-052"> ... </quote> ``` With a bit of programming, that could also display the corresponding passages. For the HTML output you linked to, you’d just precede what you currently have with a transformation step that adds a tei:note to each tei:quote with the content corresponding to each of the @corresp links. If you need something more versatile, you could use tei:linkGrps to collect all the links between the tei:lg in the Sārasamuccaya and in the MBh (https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/ref-link.html). In this case, you could encode: ``` <linkGrp> <link target="#yathA-samudro-id path-to-your-mbh-in-tei.xml#MBh01-056-027"/> <link target="#yathA-samudro-id path-to-your-mbh-in-tei.xml#MBh18-005-052"/> </linkGrp> ``` With this approach, you could also add useful attributes (@type, @ana) to the relation between the two targets. E.g., <link ana="#diff-pāda-c #diff-pāda-a"/> (just guessing here). For *documenting* the differences, I’m not quite clear on the situation: would a difference to “the MBh critical edition as far as it had been published by the early 1960s” ever actually make you change the text you’re editing? I ask because I don’t know how relevant the MBh edition is for this Sārasamuccaya as transmitted on Bali. If you do the change the text for that reason, then I’d generally follow the traditional tei:app/tei:rdg model that you outline. But if not, then I’d think adding a note with the stanza as it appears in the MBh edition would be sufficient. Depends on the intended audience and your time, of course. You could review the section on the “Alignment of Parallel Texts”: https://tei-c.org/Vault/P5/4.1.0/doc/tei-p5-doc/en/html/SA.html#SACSAL I’ve published something that might help as well: https://journals.openedition.org/jtei/3324 By the way, there’s a MBh TEI edition (“Southern recension”) in SARIT, https://github.com/sarit/SARIT-corpus/blob/master/mahabharata-devanagari.xml. Not sure if that’s any help in this regard. Best wishes, On Sun, Nov 14 2021, Arlo Griffiths wrote:
Dear colleagues,
I am trying to find a realistic path toward finalizing my digital edition of Vararuci’s Sārasamuccaya, an anthology of stanzas on Dharma (mainly from the Mahābhārata) transmitted on Bali, with Old Javanese paraphrase. The text was edited by Raghu Vira (1962).
Raghu Vira. 1962. Sāra-Samuccaya (a Classical Indonesian Compendium of High Ideals). Śata-Piṭaka Series (Dvīpāntara-Piṭaka), 24 (7). New Delhi: International Academy of Indian Culture.
This edition is in two scripts, Balinese and Devanagari, which need to be compared systematically because there are rather frequently variants vetween the two (suggestive of error in one of the two, my job being to determine which reading is more likely to have been found in the manuscripts). The edition has a critical apparatus that gives some variant readings for the Sanskrit stanzas and tries to match them with verses from the MBh critical edition as far as it had been published by the early 1960s. One of the most time consuming parts of my task as TEI editor is to double check the MBh parallels and encode the results of my findings.
My XML code is here: <https://github.com/erc-dharma/tfd-nusantara-philology/blob/master/editions/DHARMA_CritEdSarasamuccayaVararuci.xml>
A provisional display is here: <https://erc-dharma.github.io/tfd-nusantara-philology/output/critical-edition/html/DHARMA_CritEdSarasamuccayaVararuci.html>
I don’t have at my disposal a TEI version corresponding to the GRETIL file mbh1-18u.htm — can one of you oblige? As long as I don’t have one, it means that (for my XML file to validate) I need to manually apply <lg> and <l> tags and assign @n values to all <l> tags for any MBh parallel to be cited under a given Sārasamuccaya stanza. This is a lot of work and a distraction from other parts of my main task, which is to check the accuracy of the romanized Sanskrit and Old Javanese, keyed from Raghu Vira’s edition, and watching out for any differences between the Balinese and the Devanagari readings.
In this connection, I am wondering how useful it actually is, for instance, to quote
MBh01,056.027 MBh18,005.052 yathā samudro bhagavān yathā ca himavān giriḥ khyātāv ubhau ratnanidhī tathā bhāratam ucyate
below Sārasamuccaya stanza 2
yathā samudro’timahān yathā ca himavān giriḥ| ubhau ratnanidhī khyātau tathā bhāratam ucyate||
Disregarding for now the possible existence of significant variant readings both within the Mbh transmission and within that of the Sārasamuccaya (I haven’t yet checked), and how such data might be incorporated into my edition, the utility of citing the two parallel stanzas from the MBh critical edition is presumably twofold:
(1) to communicate to the reader of my edition that the given stanza has parallels in the critical edition of the MBh and where those parallels can be found (2) to underline the difference of reading in pāda c
To achieve purpose (1), I don’t need to quote the whole parallel. To achieve purpose (2), merely quoting the parallel is not very efficient. It would presumably be better to create an <app> inside the edition of the Sārasamuccaya and report the MBh reading as <rdg> — I am wondering if I should do all of the above or if <note corresp="MBh01,056.027 MBh18,005.052"> without actually citing the text of the MBh crit. ed. would be enough if I encode the variation of reading <app> inside the edition of the Sārasamuccaya stanza.
I would be grateful for suggestions from experienced TEI editors on how to achieve a useful TEI edition while avoiding needless work that stands in the way of my finishing the job.
Best wishes,
Arlo Griffiths
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
-- Patrick McAllister long-term email: pma@rdorte.org
With a bit of programming [of @corresp], that could also display the corresponding passages. I've got a need for that too, for the Sushrutaproject.org. Maybe we should club together and hire someone to do the programming?

Dear Arlo, Patrick, Domink, and world, Not sure if this is what you're looking for, but you could try the Sanskrit text alignment tools I put together: https://chchch.github.io/sanskrit-alignment/docs Step 1: Make a file like this: >Ss yathā samudro 'timahān yathā ca himavān giriḥ| ubhau ratnanidhī khyātau tathā bhāratam ucyate|| >MBh yathā samudro bhagavān yathā ca himavān giriḥ khyātāv ubhau ratnanidhī tathā bhāratam ucyate >MBhS yathā samudro bhagavān yathā merumahāgiriḥ ubhau khyātau ratnanidhī tathā bhāratam ucyate Step 2: run the helayo text alignment program on it Step 3: open in the matrix editor and correct any mis-alignments Step 4: Export as TEI apparatus. Result: yathā samudro <app n="12"><lem>'timahān </lem><rdg wit="#MBh #MBhS">bhagavān </rdg></app> yathā <app n="24"><lem wit="#MBh">ca himavān </lem><rdg wit="#MBhS">merumahā</rdg></app> giriḥ| <app n="38"><lem>ubhau ratnanidhī khyātau </lem><rdg wit="#MBh">khyātāv ubhau ratnanidhī </rdg><rdg wit="#MBhS">ubhau khyātau ratnanidhī </rdg></app> tathā bhāratam ucyate|| Best, Charles On 2021-11-19 01:39, Dominik Wujastyk wrote:
With a bit of programming [of @corresp], that could also display the corresponding passages.
I've got a need for that too, for the Sushrutaproject.org. Maybe we should club together and hire someone to do the programming?
_______________________________________________ Indic-texts mailing list Indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
{kind=link}
participants (8)
-
 Andrew Ollett
Andrew Ollett -
 Arlo Griffiths
Arlo Griffiths -
 Camillo Formigatti
Camillo Formigatti -
 Charles Li
Charles Li -
 Dominik Wujastyk
Dominik Wujastyk -
 Dániel Balogh
Dániel Balogh -
 Patrick McAllister
Patrick McAllister -
 Peter Scharf
Peter Scharf