Re: [Indic-texts] some problems with encoding parts of akṣaras in manuscript transcriptions

Hi Andrew! So brave to be the first person to post! I have also struggled in silence and darkness with those very problems which you describe. For the first issue -- vowel signs being added and deleted -- I do something similar, but using slightly non-canonical TEI. I actually include the consonant inside a <subst> tag to make explicit the fact that it's that consonant being modified. So, for example, abhi<subst>dh<del rend="implied">a</del><add>ā</add></subst>ne This has the added advantage of making it easier to render this in devanāgarī and other abugida scripts. See here: http://saktumiva.org/wiki/dravyasamuddesa/17-chennai?upama_scroll=c3.2.6-1 and the same in devanāgarī: http://saktumiva.org/wiki/dravyasamuddesa/17-chennai?upama_scroll=c3.2.6-1 in malayālam: http://saktumiva.org/wiki/dravyasamuddesa/17-chennai?upama_scroll=c3.2.6-1&upama_script=malayalam and telugu: http://saktumiva.org/wiki/dravyasamuddesa/17-chennai?upama_scroll=c3.2.6-1&upama_script=telugu With regards to the second issue -- I also have this problem, but I have yet to find an elegant and simple way to encode it. It would be such a chore to split an akṣara into parts every time you hit a string hole or a line break... Best wishes, Charles

On Sun, Apr 01 2018, Charles Li wrote:
Hi Andrew! So brave to be the first person to post!
Indeed, congratulations!
I have also struggled in silence and darkness with those very problems which you describe. For the first issue -- vowel signs being added and deleted -- I do something similar, but using slightly non-canonical TEI. I actually include the consonant inside a <subst> tag to make explicit the fact that it's that consonant being modified. So, for example,
abhi<subst>dh<del rend="implied">a</del><add>ā</add></subst>ne
I use something quite similar in my transcriptions, e.g. for the correction of /nti/ to /nte/ (see the image I’m trying to attach) I have this: <subst ana="#subst-vowel-addition"><del>न्ति</del><add>न्ते</add></subst> The main difference to Charles’ solution is that I put the whole akṣara into the del and add elements, which is of course not very precise. But for my current project I made up my mind that I would treat the conjuncts as units that I wouldn’t split up any further. I try to compensate for this by adding an analysis attribute, which at least let’s me easily query for classes of corrections/changes. My reasons for doing this were two (and I should add that they are not so strong that I’d like to recommend this as a general solution): First, the transliteration would be easy from this kind of markup: nti -> न्ति -> ন্তি -> nti works fine. But consider Andrew’s case of split vowel-signs, where we would have to transliterate something like this: ḷ<del rend="cross">o</del><add type="implicit">a</add> What should the result look like? ऌ्<del rend="cross">ो</del><add type="implicit">?</add> This is not the same as the rendering problem: it seems to me the implicit ‘a’ vowel cannot be put in the add element in certain kinds of encoding. So, unless I’m missing something, you would have to change the markup to accomodate the encoding you choose: the XML would have to change depending on whether you want to see this in an encoding that has the implicit vowel “a” or not. And also it’s unclear to me what the content of the add element should be if the script has implicit vowels. (Perhaps one will also have to fiddle with the virāma, but that usually works out.) One might say that this is a good reason against using this type of encoding (not Latin-based) for analytical markup/transcriptions in the first place. But I have at least one case where I can’t split the vowel signs up at all, regardless of encoding. And this was the second reason for me to treat conjuncts as units: in an early Bengali script, there was a change from “o” to “ā”, by deleting the left, preceding vertical stroke of the “o”’s sign, similar to this: কো -> কা I don’t see how one could describe this in any transcription scheme, since it would mean analyzing the “o” into two components (even in the Bengali Unicode block, the “o” vowel sign is just one point). I saw no way around this apart from a graphical analysis of the problem. So I decided to just encode changes from one whole conjunct to another, and link this up with an analysis of the type of correction/change that was employed. I also, like Peter, link these things to pictures when possible so that it’s easier to see what’s going on in each individual case. This doesn’t solve the second problem Andrew mentioned, the “flying r” preceded by a stringhole. I’ve never had to encode this kind of thing, where the phonological and graphical characteristics are inverse, and so can’t say much about it. Peter’s solution seems useful to me (adding sequence attributes to make the situation clearer). Theoretically, one could also introduce a special character to transliterate the “flying r”, something like this (spaces added): mā gg<gap/>Xa ṁ (or should it be “mā gg<gap/>aX ṁ”?) where “X” is the “flying r”. The drawback would of course be that the rendering issues would be pretty hard to solve: you’d need to transform all “X” into an “r” preceding the last cluster of consonants, plus you would then not be able to represent the stringhole in its proper place anymore. But this seems like much more of a bother than dealing with @part attributes. I’d also be happy to hear other solutions to these two problems! Best wihes, -- Patrick McAllister
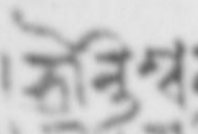{kind=link}

Hi, it is nice to read your questioning, Andrew, and reflections on it! It seems to me that these problems have a deeper issue in the background, namely (even though "we all know how an abugida works") are we reflecting how Devanagari and similar scripts function when we encode them? Or do we rather use a way of thinking about writing that is quite familiar for us (our Roman types) when we speak of "delete", "add", of virama as a sign that deletes a, or of vowels as distinct letters, etc.? The smallest unit of transcription is for me (as for Patrick) the akshara. I try to think of what a copyist did in terms of "changing x to y by doing z": he changed "ro" to "ra" by crossing the o-element. As regards flying signs on top of aksaras, or elsewhere, resulting in signs removed from the expected position: cases I am familiar with are due to the flux of writingor other aesthetic reasons, and reflect the range of freedom the copyist had in reproducing that kind of akshara. In other words, they represent a context-based way of writing that akshara; so, as they do not produce ambiguities, I would only illustrate the phenomenon in the description of the ms. Handwriting can be quite free, but there are cases in print too. In early prints in Devanagari, there are cases of "hn." printed as "n.h", which suggests a practical solution to a problematic conjunction when the types were made. In Tibetan prints, I have repeatedly seen an "e" on top of the next letter when there is not enough space for such an "e" on top of the letter to which it should be assigned. Best wishes, cristina Am 02.04.2018 um 13:47 schrieb Camillo Formigatti:
(Sorry, I sent the first one by mistake!)
Dear Andrew, Peter, and Charlie,
Finally somebody started a thread!
If you don't mind my being very direct in what I write (I'm smiling, I assure you, because I totally share your doubts about how to mark up such cases), similar questions will always come up if we don't think starting from basic problems regarding how we look at manuscripts. We ought to first agree about the way we describe manuscripts and only then we can start to ask ourselves how to mark up. I believe two questions ought to be asked first (Peter partly pointed out already the first one in his reply): why mark up such phenomena? Also, I would add: to which degree of exactness?
As to the first question, there are obvious answers, such as if I'm preparing a diplomatic transcription or a critical edition, I have to do it. Then how? All solutions proposed entail the use of the elements <del></del> and <add></add>, as well as <subst></subst> (as in Charlie's example, who I guess is partly adopting our Cambridge standards), thus with the basic structure <subst><del></del><add></add></subst>. I totally agree with this approach, but...
Now let me answer to the first possible objection: in Andrew's example, is the scribe really adding something? Sure he is (let's not get politically correct, we know it was almost certainly a man, even if there is no colophon in the manuscript). He is not materially adding anything on the folio, sure, but what are we marking up? Let's say he wanted to substitute o with ā, then he would have added a mātrā, right? As we all know, the functioning of an abugida writing system rests on the principle of an inherent vowel. The point here is "as we all know." We are marking up transcriptions of manuscripts in scripts of which we know the functioning, so no need to get more catholic than the pope. Also, to a certain extent the scribe was substituting something with something else, by deleting an o and adding an a (or in other cases, a mātrā for any other vowel). I think that this is an elegant way of solving the "implicit" problem, though without using any further element or attribute.
The answer to my second question might also provide an answer to Andrew's second conundrum. In our catalogue we adopted two attributes for deletions and additions: for <add></add> we used @place to mark where the addition was made (using the standard values provided in the ENRICH schema), and for <del></del> we used the @type (values =yellow_paste, expuncted, erased, palimpsest, cancelled). I don't know if we can agree about the number or typology of attributes to be used, but this is not so important, as we will always have slightly different approaches, for as Peter pointed out, we have usually have different aims when describing manuscripts.
Thinking of the approach I have described above, the "we all know how an abugida works" argument might also solve the conundrum of marking up a whole akṣara or only a part. With this approach, there is no need to mark up only parts of an akṣara, as it is clear that only the mātrā was changed. (Also, no problem for cases of akṣaras divided by string holes, we can always nest the elements, if I get the problem–but I'm not really sure to have understood it.)
A belated Happy Eater to you all!
Camillo
________________________________________ From: indic-texts-bounces@lists.tei-c.org [indic-texts-bounces@lists.tei-c.org] on behalf of indic-texts-request@lists.tei-c.org [indic-texts-request@lists.tei-c.org] Sent: Sunday, April 01, 2018 11:00 AM To: indic-texts@lists.tei-c.org Subject: indic-texts Digest, Vol 3, Issue 1
Send indic-texts mailing list submissions to indic-texts@lists.tei-c.org
To subscribe or unsubscribe via the World Wide Web, visit http://lists.lists.tei-c.org/mailman/listinfo/indic-texts or, via email, send a message with subject or body 'help' to indic-texts-request@lists.tei-c.org
You can reach the person managing the list at indic-texts-owner@lists.tei-c.org
When replying, please edit your Subject line so it is more specific than "Re: Contents of indic-texts digest..."
Today's Topics:
1. some problems with encoding parts of ak?aras in manuscript transcriptions (Andrew Ollett) 2. Re: some problems with encoding parts of ak?aras in manuscript transcriptions (Peter Scharf)
----------------------------------------------------------------------
Message: 1 Date: Sat, 31 Mar 2018 22:50:16 -0500 From: Andrew Ollett <andrew.ollett@gmail.com> To: indic-texts@lists.tei-c.org Subject: [Indic-texts] some problems with encoding parts of ak?aras in manuscript transcriptions Message-ID: <CAANHO15y_K1BRZLqj+PauXoxcvdgusDS1Df99juUp+W7xkV-Lg@mail.gmail.com> Content-Type: text/plain; charset="utf-8"
Hi everyone,
I have two questions about encoding manuscript transcriptions that I wanted to submit to the collective experience of this group. Both relate to the problem of ak?aras having "parts" that canonically occur in a certain sequence but may be changed in a manuscript.
First, the cancellation of vowel m?tr?s. Does anyone have a good way to encode this in TEI? In one manuscript (see this link <https://goo.gl/uYxV3R>) the scribe has written "yo?do?da?o?o?a" (the last letter being mostly obliterated by a worm hole), and cancelled out the last "o" (which is written with the sideways "3") with a small cross-mark on top. The problem is that by cancelling out the m?tr?, the scribe has changed the vowel. Since we are transcribing in Roman transliteration, we would have to do something like yo?do?da?o?<del rend="cross">o</del><add type="implicit">a</add>?a, i.e., marking the addition of the vowel as "implicit" (or something similar) in order to make clear that it's not a new mark on the leaf. (If we were transcribing in Kannada script, we could do ??????????<del>?</del>?, but that will surely cause rendering problems.)
Second, the "canonical" order of code-points and of transliteration for conjuncts with initial r has the r first. In Kannada script, however, a "flying r" is used, which occurs to the right of the other consonants in the conjunct. Sometimes there's a feature that we want to encode *between* the members of the conjunct, as in this example <https://goo.gl/BqNVg9>, where a string-hole intervenes between the "gg" and the "r" of "m?rgga?". How should we encode this? I know that some of you have used "ak?arapart" to identify m?tr?s and other components of ak?aras, but I can't seem to get around the problem of the reversed sequence of the phonological representation and the graphic representation.
Grateful for any help!
Andrew

Hello all, and let me add my thanks to Andrew for starting a thread. I've read your opinions with interest and have little new to add, but here are my thoughts anyway. My approach is based on encoding texts in Romanised form (whether IAST or SLP doesn't matter). My basic feeling is that marking up every little feature may not be worth the trouble. I believe this is what Camillo has been suggesting and what Peter has shown in his example. So reflecting changes on the level of phonemes should be fine, and a change of one vowel to another can be marked up simply as <subst><del>o</del><add>ā</add></subst>. The deletion and the addition could be qualified with attributes as in Andrew's original post. I believe the generic solution (recommended in EpiDoc) would serve well: <subst><del rend="corrected">o</del><add place="overstrike">ā</add></subst> Exactly how this change is implemented graphically in the written specimen is, as Camillo says, something that can be left to the reader's knowledge of the writing system in question; or, in the rare cases where we as editors think it will not be obvious to anyone who cares, described in a comment for human readers only. The same would work for the deletion of vowel mātrās i.e. correction of another vowel to "a". Or, if the a is described as implicit for the sake of precision, I would still suggest using the @place attribute with that value, not @type. If it is desired that the encoded text can be rendered in an Indic script, we must keep in mind that this is mainly for the sake of modern readers who are more familiar with those scripts than Romanisation. In most cases, rendering in a Devanagari or Kannada or whatever font will not be a 100% accurate representation of the way complex akṣaras are constituted in the MS. So, in my mind, this is a display issue that needs to be dealt with in the XSLT that produces human-readable output from your markup. Wrapping the entire akṣara in a <c> element may make the transformation a lot easier. This is similar to what Charles is doing with <subst> but, I believe, entirely canonical. Using <c> to wrap akṣaras may also be an idea to consider for Andrew's second problem, though of course it doesn't solve the problem of the floating r. All the best, Dan

Dear all, I was delighted, though not entirely surprised, to see that many of you had grappled with similar issues. I sketched out the issues briefly and wrote up some of the solutions that you've suggested here: https://wiki.tei-c.org/index.php/SIG:IndicTexts (I found Paddy's example from early Bengali script extremely useful, but I didn't presume to add it to the wiki without asking.) Transliteration promises to be a persistent issue: many encoding strategies just don't make sense if we are either inputting our texts in Indic scripts or providing for output in Indic scripts. It's not clear to me at this point how worried I should be about this: in our project, the only reason for offering a Kannada-script version of the manuscript transcriptions is "why not?". But if we did need a principled approach, the use of wrappers like <c> (or <g>?) might help. I also tried looking at the ENRICH guidelines after Camillo mentioned them. I couldn't locate a schema file, and in the online documentation (there are lots of broken links) I didn't see any specification of attribute values for @type (in <del>) or @place (in <add>). But I tried to stick to what Dániel and Camillo recommended. Thanks everyone, and please feel free to suggest additions or modifications to the TEI Wiki page (anyone with a TEI account can edit as well). Andrew 2018-04-04 4:06 GMT-05:00 Balogh Dániel <danbalogh@gmail.com>:
Hello all, and let me add my thanks to Andrew for starting a thread. I've read your opinions with interest and have little new to add, but here are my thoughts anyway.
My approach is based on encoding texts in Romanised form (whether IAST or SLP doesn't matter). My basic feeling is that marking up every little feature may not be worth the trouble. I believe this is what Camillo has been suggesting and what Peter has shown in his example. So reflecting changes on the level of phonemes should be fine, and a change of one vowel to another can be marked up simply as <subst><del>o</del><add>ā</add></subst>. The deletion and the addition could be qualified with attributes as in Andrew's original post. I believe the generic solution (recommended in EpiDoc) would serve well: <subst><del rend="corrected">o</del><add place="overstrike">ā</add></subst> Exactly how this change is implemented graphically in the written specimen is, as Camillo says, something that can be left to the reader's knowledge of the writing system in question; or, in the rare cases where we as editors think it will not be obvious to anyone who cares, described in a comment for human readers only. The same would work for the deletion of vowel mātrās i.e. correction of another vowel to "a". Or, if the a is described as implicit for the sake of precision, I would still suggest using the @place attribute with that value, not @type.
If it is desired that the encoded text can be rendered in an Indic script, we must keep in mind that this is mainly for the sake of modern readers who are more familiar with those scripts than Romanisation. In most cases, rendering in a Devanagari or Kannada or whatever font will not be a 100% accurate representation of the way complex akṣaras are constituted in the MS. So, in my mind, this is a display issue that needs to be dealt with in the XSLT that produces human-readable output from your markup. Wrapping the entire akṣara in a <c> element may make the transformation a lot easier. This is similar to what Charles is doing with <subst> but, I believe, entirely canonical. Using <c> to wrap akṣaras may also be an idea to consider for Andrew's second problem, though of course it doesn't solve the problem of the floating r.
All the best, Dan
_______________________________________________ indic-texts mailing list indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts

Andrew, thanks for your clear summary of the issues just discussed regarding the deletion and addition of syllable fragments. There are two more general issues that I think need to be considered in this discussion: 1. Graphic versus phonetic encoding. 2. The purpose of transcription. The first issue is discussed at some length in Peter M. Scharf and Malcolm D. Hyman. 2010. Linguistic Issues in Encoding Sanskrit. The book is available as a PDF at the following link: http://www.sanskritlibrary.org/publications.html <http://www.sanskritlibrary.org/publications.html> Unicode Indic scripts are not consistent in being either phonetic or graphic but are somewhere between. Hence the problems with differently ordered graphic elements requiring differently ordered encoding in Unicode. In our book we briefly discussed what segmental and featural graphic encodings for Devanagari would look like, but did not detail either such encoding. If one really wants to solve transcription issues down to the detail of fragments of syllables, one requires a featural encoding of the Indic script in question. What this means, for example, is that a mAtrA has a separate code point, the base of an o and A has a separate code point from the top of the o, etc. If this were the case, the problems raised would have precise solutions. The second point, however, raises the question of whether such detail is worth the trouble. In my opinion it is not though some may disagree. I think it is not because computer graphics is at such a stage that it is trivial to insert or share an image where such considerations are relevant. For the meaning of the text, such considerations are not at all relevant, and it is ultimately the meaning of texts that is of interest. Since scripts are a way of encoding a language and the language is a phonetic entity, it is the phonetic sequence that is relevant, not the graphic representation of that sequence. This is the reason for the invention and use of the Sanskrit Library Phonetic (SLP) encodings and the production of a thorough set of transcoding routines to transcode SLP into standard Romanizations, other metaencodings, and Indic scripts. Lastly, one final question I have is this: Has any circumstance arisen in mss transcription where a del followed immediately by an add is not a subst? And if a something intervenes between the del and the add, can it rightly be called a subst? I don't know of a positive answer to either of these questions and therefore question the utility of the subst element. But if someone can show such a prayojana, I'm interested to see it. Yours, Peter ****************************** Peter M. Scharf, President The Sanskrit Library scharf@sanskritlibrary.org http://sanskritlibrary.org ******************************
On 10 Apr. 2018, at 8:59 AM, Andrew Ollett <andrew.ollett@gmail.com> wrote:
Dear all,
I was delighted, though not entirely surprised, to see that many of you had grappled with similar issues. I sketched out the issues briefly and wrote up some of the solutions that you've suggested here:
https://wiki.tei-c.org/index.php/SIG:IndicTexts <https://wiki.tei-c.org/index.php/SIG:IndicTexts>
(I found Paddy's example from early Bengali script extremely useful, but I didn't presume to add it to the wiki without asking.)
Transliteration promises to be a persistent issue: many encoding strategies just don't make sense if we are either inputting our texts in Indic scripts or providing for output in Indic scripts. It's not clear to me at this point how worried I should be about this: in our project, the only reason for offering a Kannada-script version of the manuscript transcriptions is "why not?". But if we did need a principled approach, the use of wrappers like <c> (or <g>?) might help.
I also tried looking at the ENRICH guidelines after Camillo mentioned them. I couldn't locate a schema file, and in the online documentation (there are lots of broken links) I didn't see any specification of attribute values for @type (in <del>) or @place (in <add>). But I tried to stick to what Dániel and Camillo recommended.
Thanks everyone, and please feel free to suggest additions or modifications to the TEI Wiki page (anyone with a TEI account can edit as well).
Andrew
2018-04-04 4:06 GMT-05:00 Balogh Dániel <danbalogh@gmail.com <mailto:danbalogh@gmail.com>>: Hello all, and let me add my thanks to Andrew for starting a thread. I've read your opinions with interest and have little new to add, but here are my thoughts anyway.
My approach is based on encoding texts in Romanised form (whether IAST or SLP doesn't matter). My basic feeling is that marking up every little feature may not be worth the trouble. I believe this is what Camillo has been suggesting and what Peter has shown in his example. So reflecting changes on the level of phonemes should be fine, and a change of one vowel to another can be marked up simply as <subst><del>o</del><add>ā</add></subst>. The deletion and the addition could be qualified with attributes as in Andrew's original post. I believe the generic solution (recommended in EpiDoc) would serve well: <subst><del rend="corrected">o</del><add place="overstrike">ā</add></subst> Exactly how this change is implemented graphically in the written specimen is, as Camillo says, something that can be left to the reader's knowledge of the writing system in question; or, in the rare cases where we as editors think it will not be obvious to anyone who cares, described in a comment for human readers only. The same would work for the deletion of vowel mātrās i.e. correction of another vowel to "a". Or, if the a is described as implicit for the sake of precision, I would still suggest using the @place attribute with that value, not @type.
If it is desired that the encoded text can be rendered in an Indic script, we must keep in mind that this is mainly for the sake of modern readers who are more familiar with those scripts than Romanisation. In most cases, rendering in a Devanagari or Kannada or whatever font will not be a 100% accurate representation of the way complex akṣaras are constituted in the MS. So, in my mind, this is a display issue that needs to be dealt with in the XSLT that produces human-readable output from your markup. Wrapping the entire akṣara in a <c> element may make the transformation a lot easier. This is similar to what Charles is doing with <subst> but, I believe, entirely canonical. Using <c> to wrap akṣaras may also be an idea to consider for Andrew's second problem, though of course it doesn't solve the problem of the floating r.
All the best, Dan
_______________________________________________ indic-texts mailing list indic-texts@lists.tei-c.org <mailto:indic-texts@lists.tei-c.org> http://lists.lists.tei-c.org/mailman/listinfo/indic-texts <http://lists.lists.tei-c.org/mailman/listinfo/indic-texts>
_______________________________________________ indic-texts mailing list indic-texts@lists.tei-c.org http://lists.lists.tei-c.org/mailman/listinfo/indic-texts
participants (6)
-
 Andrew Ollett
Andrew Ollett -
 Balogh Dániel
Balogh Dániel -
 Charles Li
Charles Li -
 cristina pecchia
cristina pecchia -
 Patrick McAllister
Patrick McAllister -
 Peter Scharf
Peter Scharf