
On Sun, Apr 01 2018, Charles Li wrote:
Hi Andrew! So brave to be the first person to post!
Indeed, congratulations!
I have also struggled in silence and darkness with those very problems which you describe. For the first issue -- vowel signs being added and deleted -- I do something similar, but using slightly non-canonical TEI. I actually include the consonant inside a <subst> tag to make explicit the fact that it's that consonant being modified. So, for example,
abhi<subst>dh<del rend="implied">a</del><add>ā</add></subst>ne
I use something quite similar in my transcriptions, e.g. for the correction of /nti/ to /nte/ (see the image I’m trying to attach) I have this: <subst ana="#subst-vowel-addition"><del>न्ति</del><add>न्ते</add></subst> The main difference to Charles’ solution is that I put the whole akṣara into the del and add elements, which is of course not very precise. But for my current project I made up my mind that I would treat the conjuncts as units that I wouldn’t split up any further. I try to compensate for this by adding an analysis attribute, which at least let’s me easily query for classes of corrections/changes. My reasons for doing this were two (and I should add that they are not so strong that I’d like to recommend this as a general solution): First, the transliteration would be easy from this kind of markup: nti -> न्ति -> ন্তি -> nti works fine. But consider Andrew’s case of split vowel-signs, where we would have to transliterate something like this: ḷ<del rend="cross">o</del><add type="implicit">a</add> What should the result look like? ऌ्<del rend="cross">ो</del><add type="implicit">?</add> This is not the same as the rendering problem: it seems to me the implicit ‘a’ vowel cannot be put in the add element in certain kinds of encoding. So, unless I’m missing something, you would have to change the markup to accomodate the encoding you choose: the XML would have to change depending on whether you want to see this in an encoding that has the implicit vowel “a” or not. And also it’s unclear to me what the content of the add element should be if the script has implicit vowels. (Perhaps one will also have to fiddle with the virāma, but that usually works out.) One might say that this is a good reason against using this type of encoding (not Latin-based) for analytical markup/transcriptions in the first place. But I have at least one case where I can’t split the vowel signs up at all, regardless of encoding. And this was the second reason for me to treat conjuncts as units: in an early Bengali script, there was a change from “o” to “ā”, by deleting the left, preceding vertical stroke of the “o”’s sign, similar to this: কো -> কা I don’t see how one could describe this in any transcription scheme, since it would mean analyzing the “o” into two components (even in the Bengali Unicode block, the “o” vowel sign is just one point). I saw no way around this apart from a graphical analysis of the problem. So I decided to just encode changes from one whole conjunct to another, and link this up with an analysis of the type of correction/change that was employed. I also, like Peter, link these things to pictures when possible so that it’s easier to see what’s going on in each individual case. This doesn’t solve the second problem Andrew mentioned, the “flying r” preceded by a stringhole. I’ve never had to encode this kind of thing, where the phonological and graphical characteristics are inverse, and so can’t say much about it. Peter’s solution seems useful to me (adding sequence attributes to make the situation clearer). Theoretically, one could also introduce a special character to transliterate the “flying r”, something like this (spaces added): mā gg<gap/>Xa ṁ (or should it be “mā gg<gap/>aX ṁ”?) where “X” is the “flying r”. The drawback would of course be that the rendering issues would be pretty hard to solve: you’d need to transform all “X” into an “r” preceding the last cluster of consonants, plus you would then not be able to represent the stringhole in its proper place anymore. But this seems like much more of a bother than dealing with @part attributes. I’d also be happy to hear other solutions to these two problems! Best wihes, -- Patrick McAllister
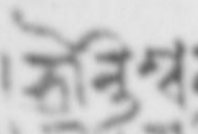{kind=link}